功能介绍
企业机器学习项目涉及海量动态资产(数据版本、特征工程、模型参数等),传统管理方式依赖人工记录实验、分散部署脚本和手动性能监控,导致流程割裂、实验难复现、响应延迟等问题,显著拖慢模型交付速度并影响生产稳定性。为解决这一瓶颈,MLOps(机器学习运维)通过构建自动化流水线框架,统一管理从数据准备到模型监控的全生命周期。结合持续集成/持续部署(CI/CD)和容器化技术,MLOps实现了实验可追溯、一键式部署及实时漂移检测,大幅提升模型生产化效率与系统可靠性,推动AI从实验室原型转化为可持续释放业务价值的核心引擎。
异常检测模型训练
第一步:数据集
新增数据集
在数据集界面,点击“新增”,填写名称,简介,新增数据集。
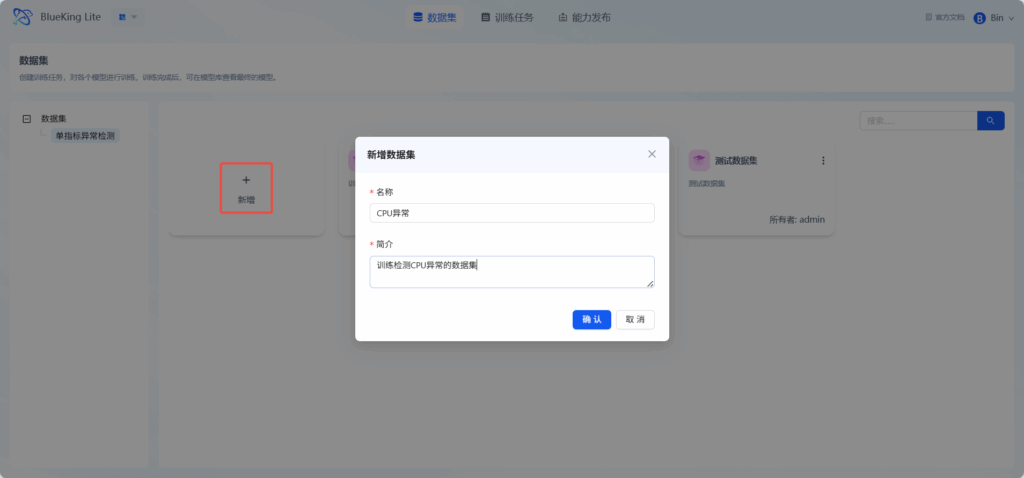
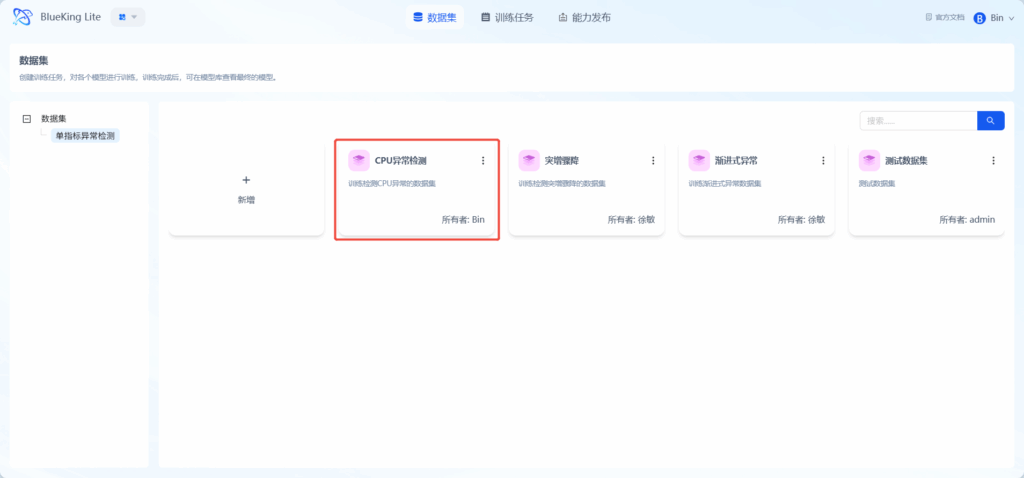
点击新增的数据集,进入数据集详情
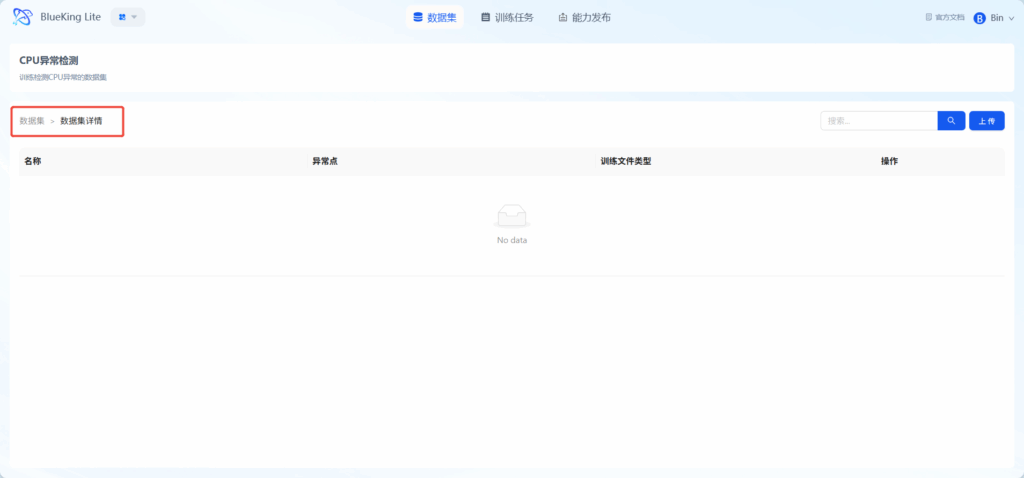
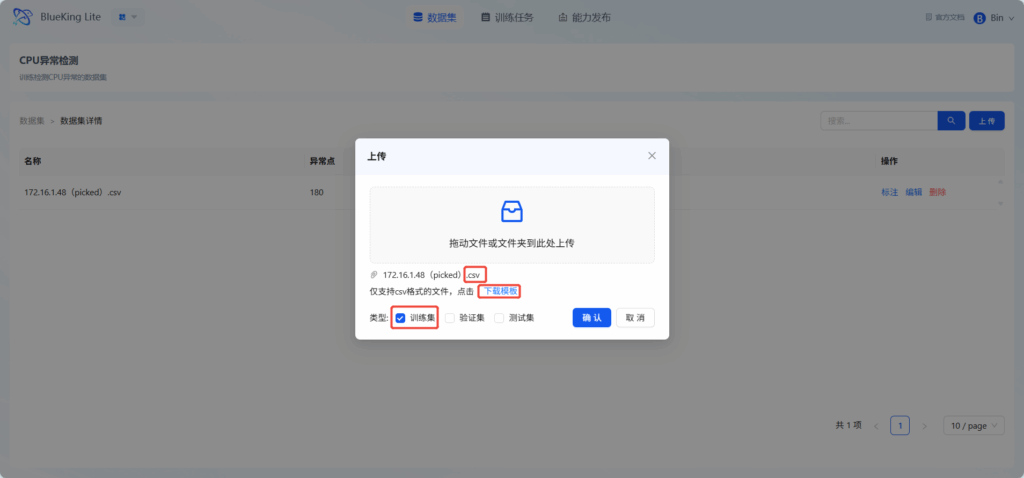
上传数据集文件
点击上传,即可上传数据集文件。(应上传csv格式的文件,其中有模板可供下载。需要选择数据集类型,分为训练集,验证集,测试集三种。)
- 训练集 —— 用于模型拟合的数据样本。在训练过程中对训练误差进行梯度下降,进行学习,可训练的权重参数。
- 验证集 —— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
- 测试集 —— 用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
标注数据集
在数据集详情中点击标注,即可标注数据集中的异常点。也可以点击编辑,进行文件类型的切换。
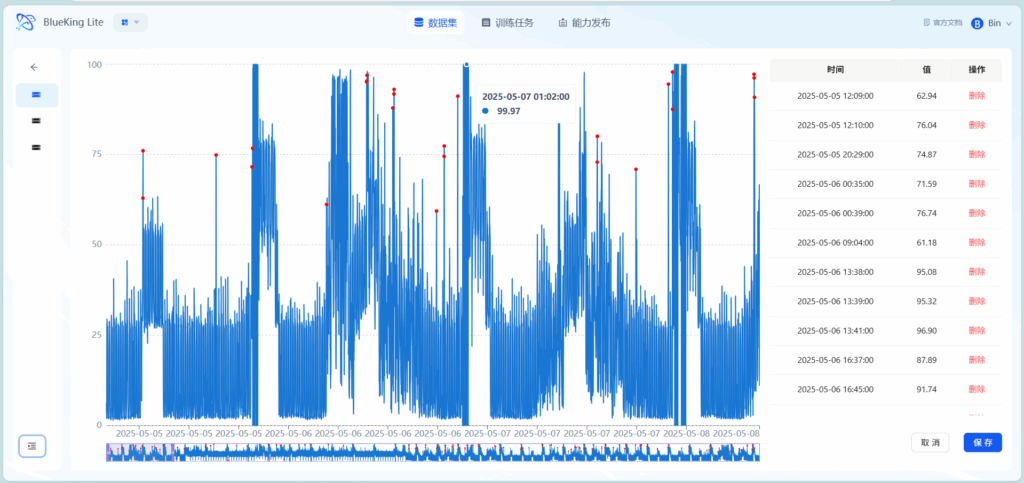
基础操作
在图中点击某个具体的点,再点击保存后即可将其标注为异常点。
如图,当光标悬浮于某一点上,即可展示那一点的时间和具体的值。也可以在点击具体的点后在右边的表格中进行查看,或进行删除操作。
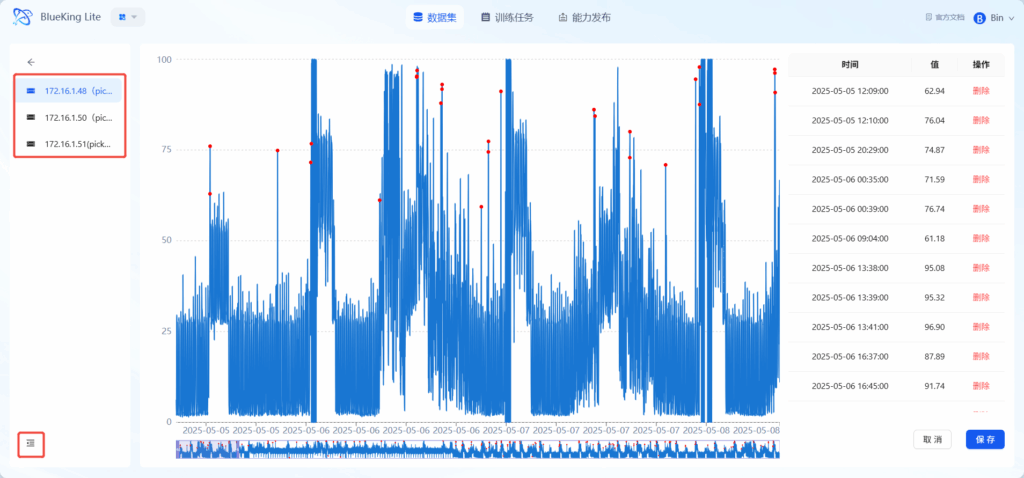
导航栏的伸缩
导航栏的伸缩:点击左下角的按键后即可实现导航栏的伸缩。
- 导航栏的展开:用户可以看到数据集下所有的文件,点击后即可实现文件间的快捷切换。
- 导航栏的关闭:用户可以在标注时将导航栏关闭,关闭后用户将拥有更大的空间进行数据集的标注。
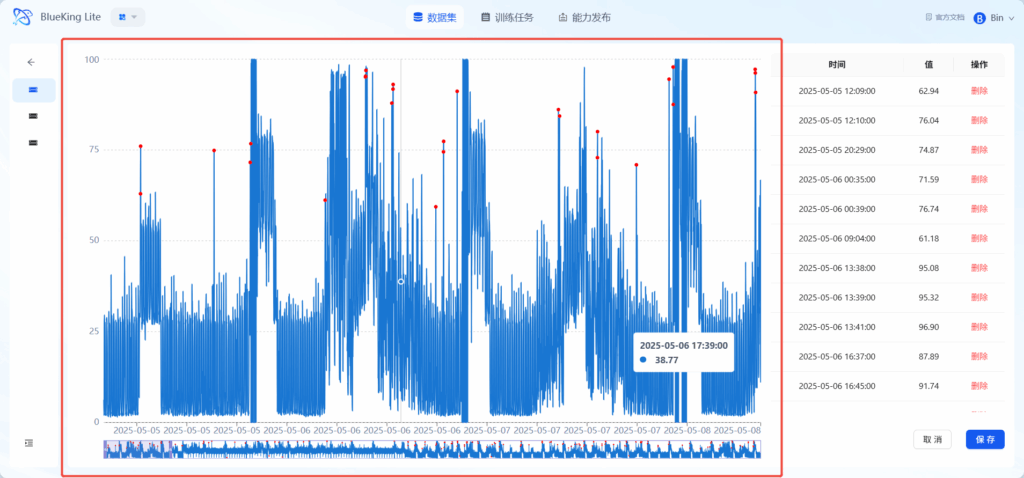
快捷标注方式
快捷标注方式:直接在图中进行一段时间的拉取,即可快速把选取的这段时间中的所有点都标注为异常点。
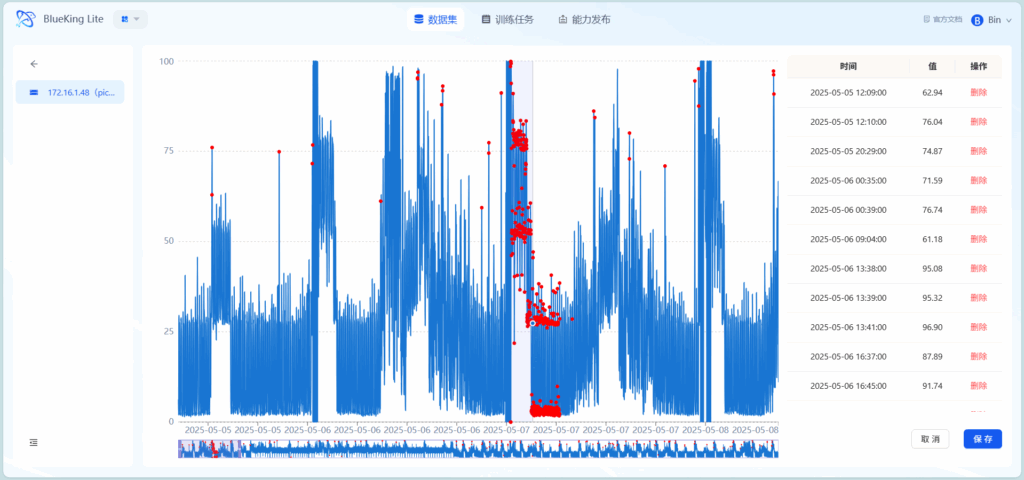
第二步:训练任务
添加训练任务
添加训练任务,填入名称,选择训练算法,可进行超参数调优,选择最大训练轮次,训练文件。
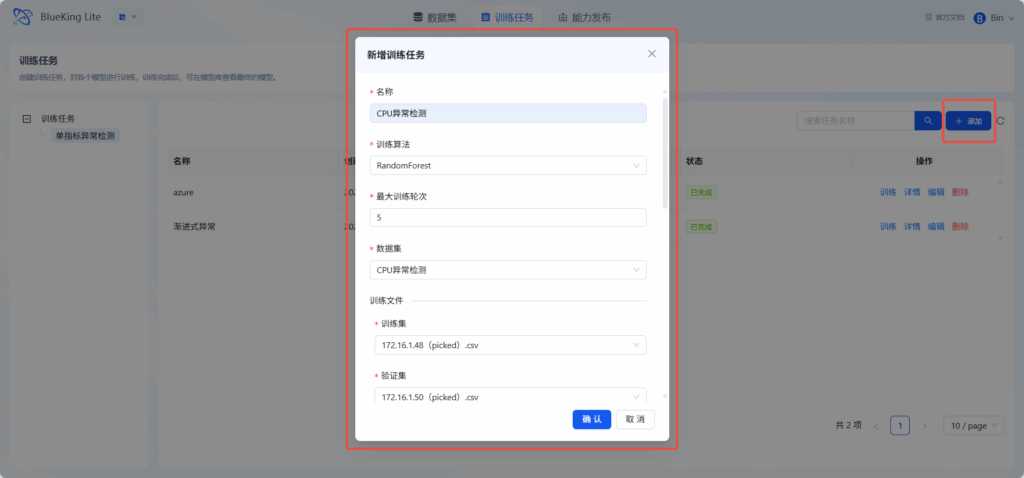
进行任务训练
添加成功后在训练任务中会有相对应的训练任务,可进行训练,详情查看,编辑,删除操作。点击训练后开始训练模型。
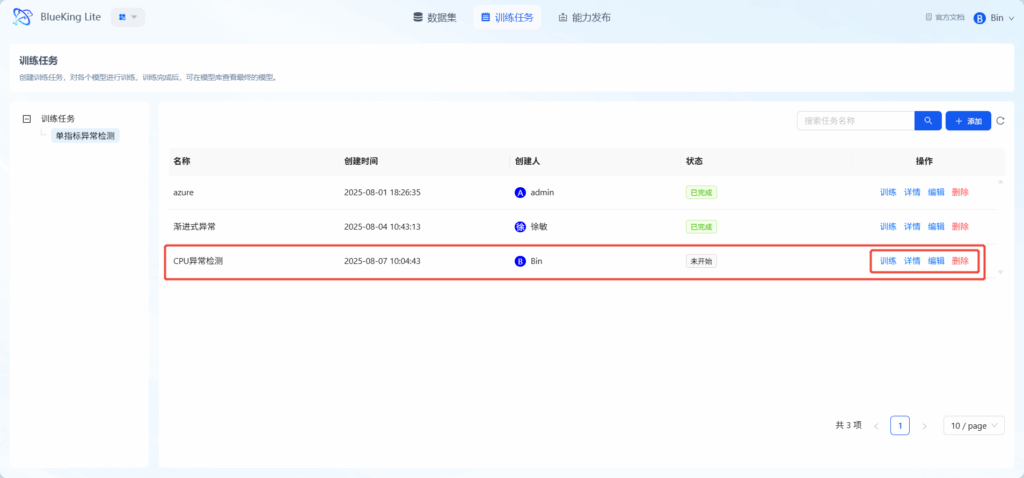
状态查看
开始训练后,可在状态中查看是否在进行中或者是已完成
第三步:能力发布
模型发布
添加模型发布:点击模型发布,输入能力名称,选择训练任务,填写模型介绍
发布上线:打开开关,即可将模型发布上线
其他能力介绍
算法
RandomForest随机森林
随机森林算法是一种由多棵决策树组成的集成算法,通过对多个决策树的结果进行投票来做出分类决策。它广泛应用于分类和回归问题中,具有出色的性能和灵活性。
| 超参数 | 含义 |
| n_estimators | 决策树个数 |
| max_depth | 决策树最大深度 |
| min_samples_split | 最小分离样本数(即拆分决策树节点所需的最小样本数) |
| min_samples_leaf | 最小叶子节点样本数(即一个叶节点所需包含的最小样本数) |
| max_features | 最大分离特征数(即寻找最佳节点分割时要考虑的特征变量数量) |
| bootstrap | 是否进行随机抽样 |
| class_weight | 每个类的权重 |